PDF parsers: A benchmark
(Code and example PDFs available at harningle/useful-scripts)
It’s now 2025, and it’s still freakingly difficult for a computer to read PDFs. The PDF format, by design, are for output, e.g. for printers or human eyes, rather than a machine readable data source. However, many LLM applications require text input. So the problem is, how can we convert a PDF to a .txt file? Below I run some popular PDF parsers on a few PDFs to convert them to Markdown files. Docling and MinerU turn out to be the best (though still many problems).
Common PDF formats
From easy to difficult, here are some PDFs that I often encounter in my day job.
Pure Text. Nothing fancy; just a bunch of text. The tricky point is to get section titles, font style (e.g. italic vs bold), footnotes, etc. correct. The example is from European Investment Bank (2023, p. viii).
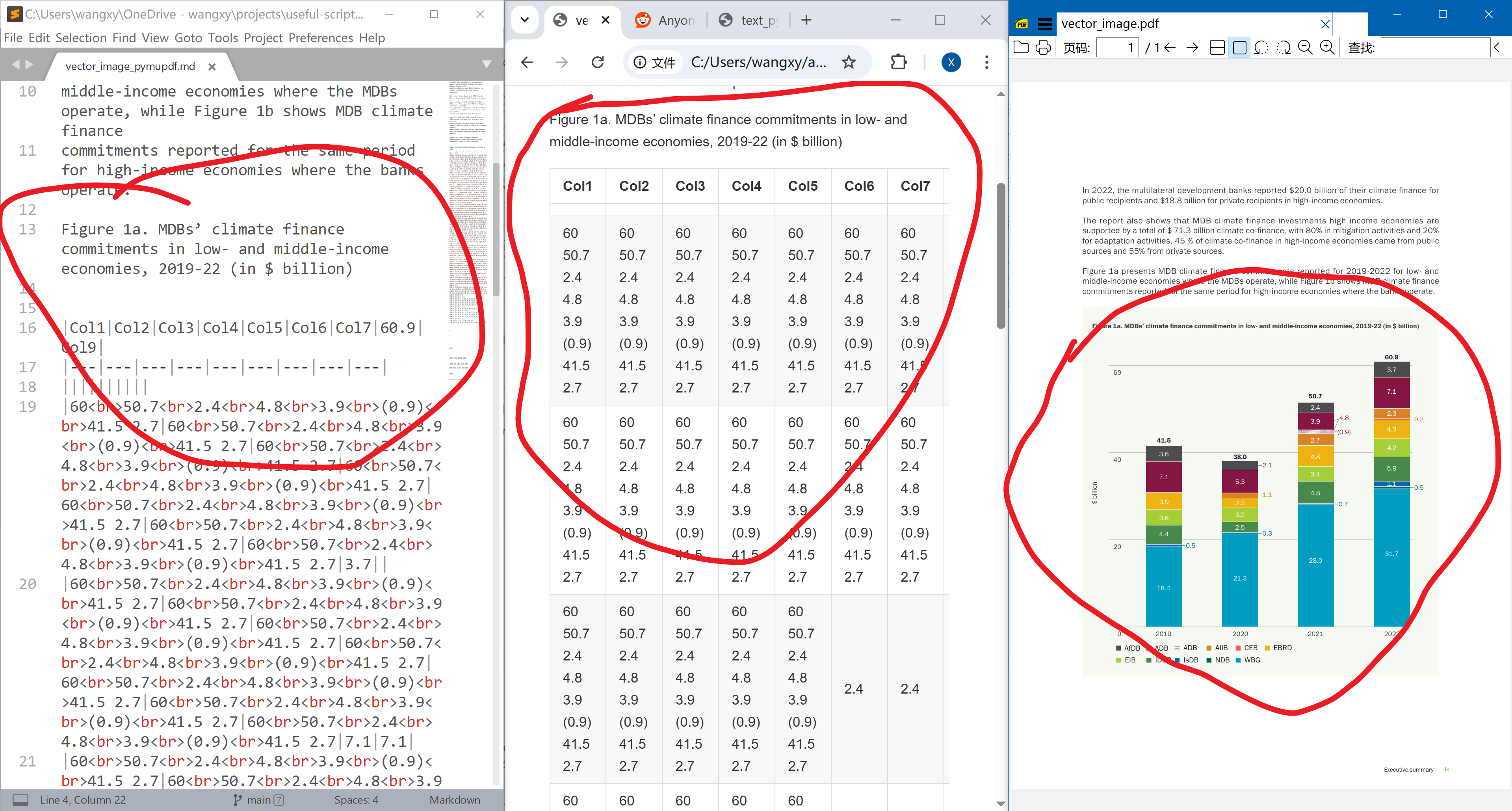
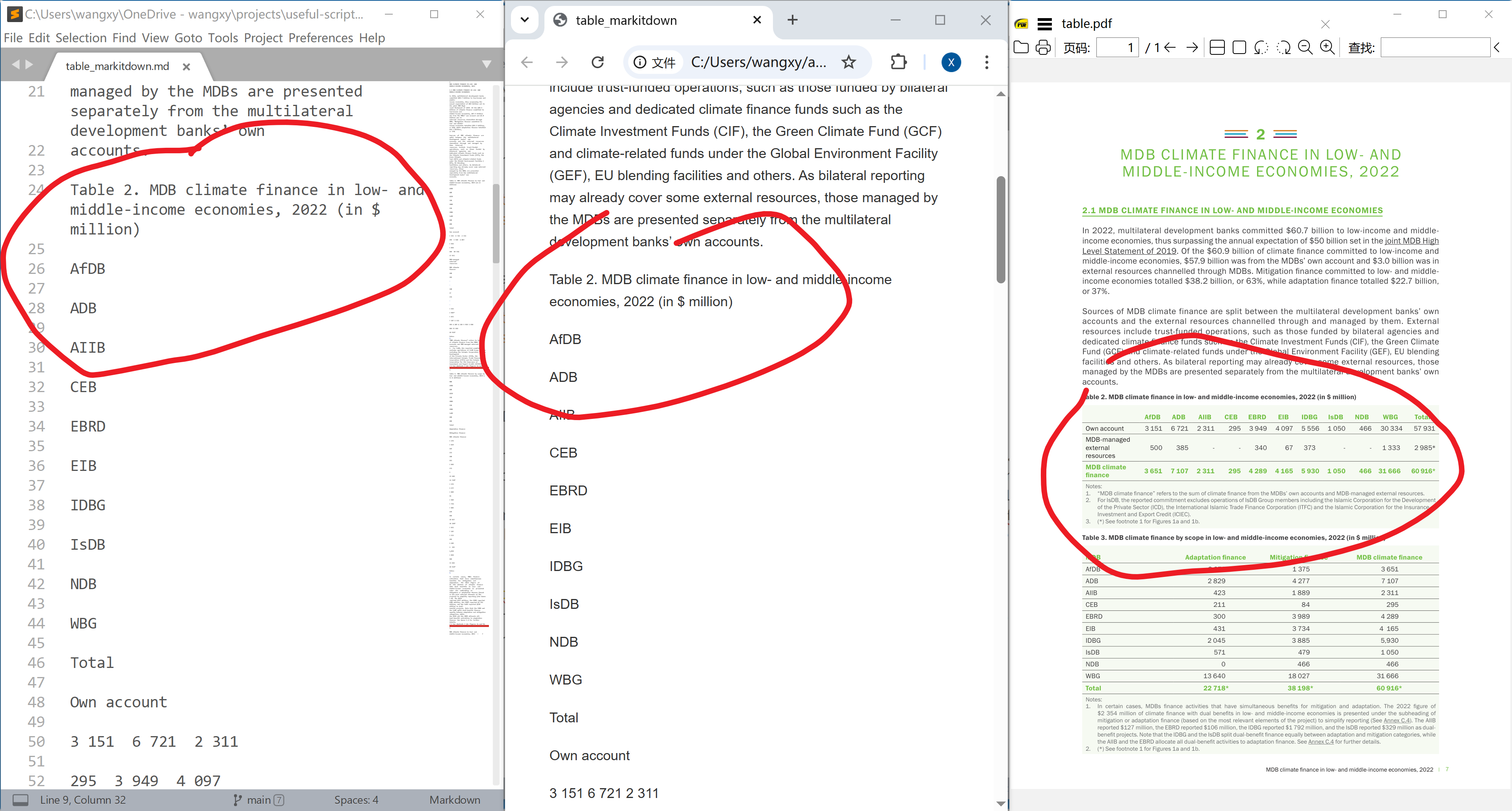
Simple Tables. Tables are especially difficult to parse, especially when there is no grid lines separating the rows and columns. The example below is also from European Investment Bank (2023, p. 7). The page has two very simple tables: there are horizontal grid lines, and tables have non-white background colours, so we can easily distinguish them with the text. A good parser should be able to handle this type of simple tables.
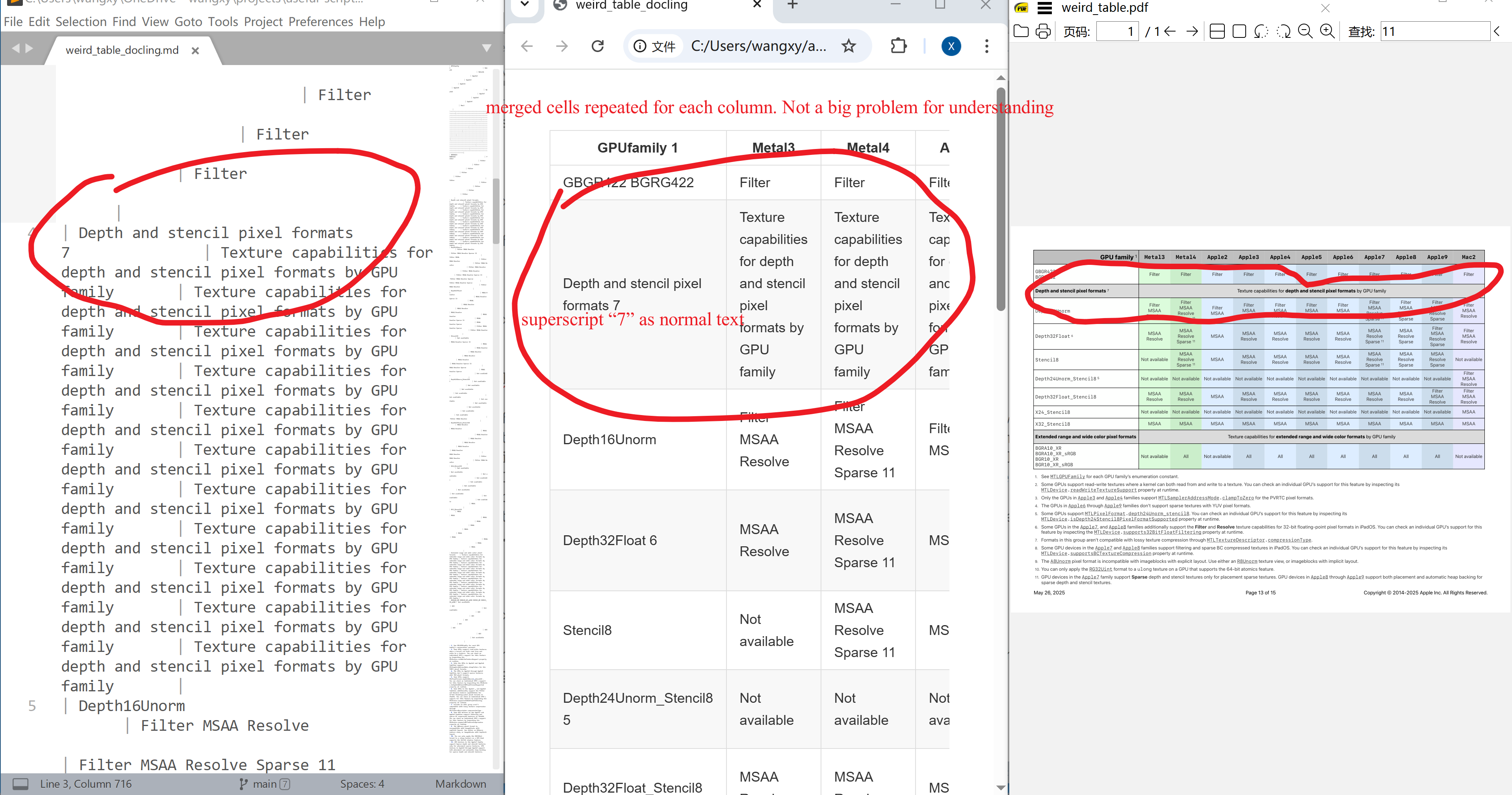
Complicated Tables. Moreover, tables can have merged cells, wrapped/multi-line text within a cell, etc. Our example is from Apple (2025, p. 13).
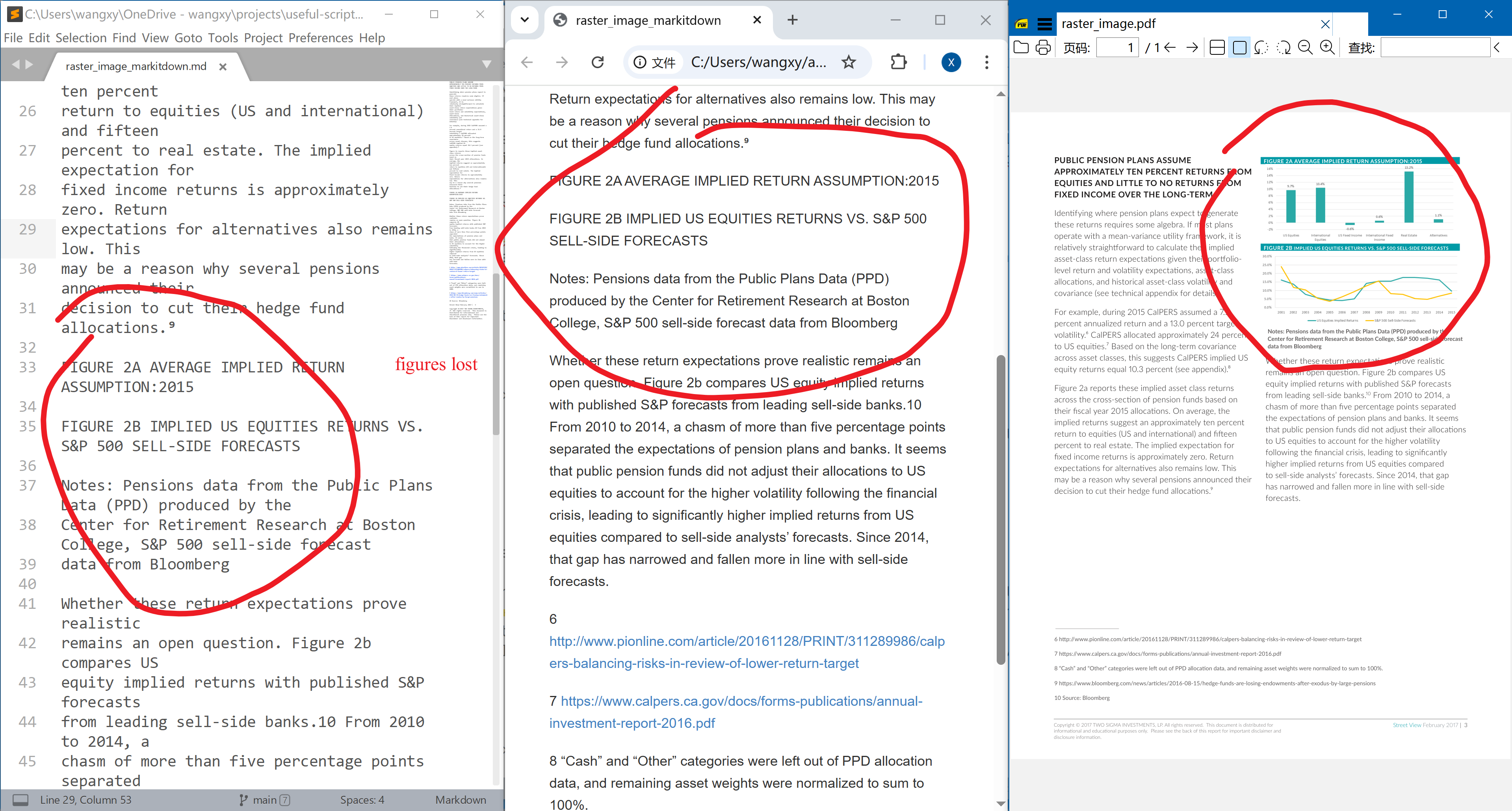
Raster Images. The parser should be able to extract the images, and tell us which image is on which page. There are two types of images, raster and vector. Raster is basically a pure image. We take an example from Two Sigma (2017, p. 3). This example not only has images, but is also a multi-column page, so we can test the parsers’ performance for this type of pages as well.
Vector Images. Vector images are slightly different from the raster. Technically they are just shapes like lines or curves, which are exactly the same as a grid line in a table. In addition, a vector image may contain text, such as numbers on the axis. These text are part of the image, rather than the usual main text. We want to treat a vector image in the same way as a usual raster. The example page is from European Investment Bank (2023, p. vix).
Parsers and results
I picked a few popular free PDF parsing packages from GitHub. And I use the default options for each of them. I know probably with some tuning we can extract more performance from them, but I’m not doing that here. All example input PDFs are single-page, and we want to convert them to a Markdown file. If there is any image in the page, the images should be save as a separate .jpg/.png file, and the Markdown should contain references to them. The test was done in June 11, 2025, using the latest version/model of all packages.
PyMuPDF4LLM
PyMuPDF is my favourite package to work with PDF. It can do almost everything: get shapes on the page, read text, get font size, locate an image, etc. All of these are done “mechanically”, in the sense that it does not use any machine learning/computer vision. The most important factor for parsing are the parameters/config. The default options are often bad.1
In our pure text example, PyMuPDF fails to detect section titles.
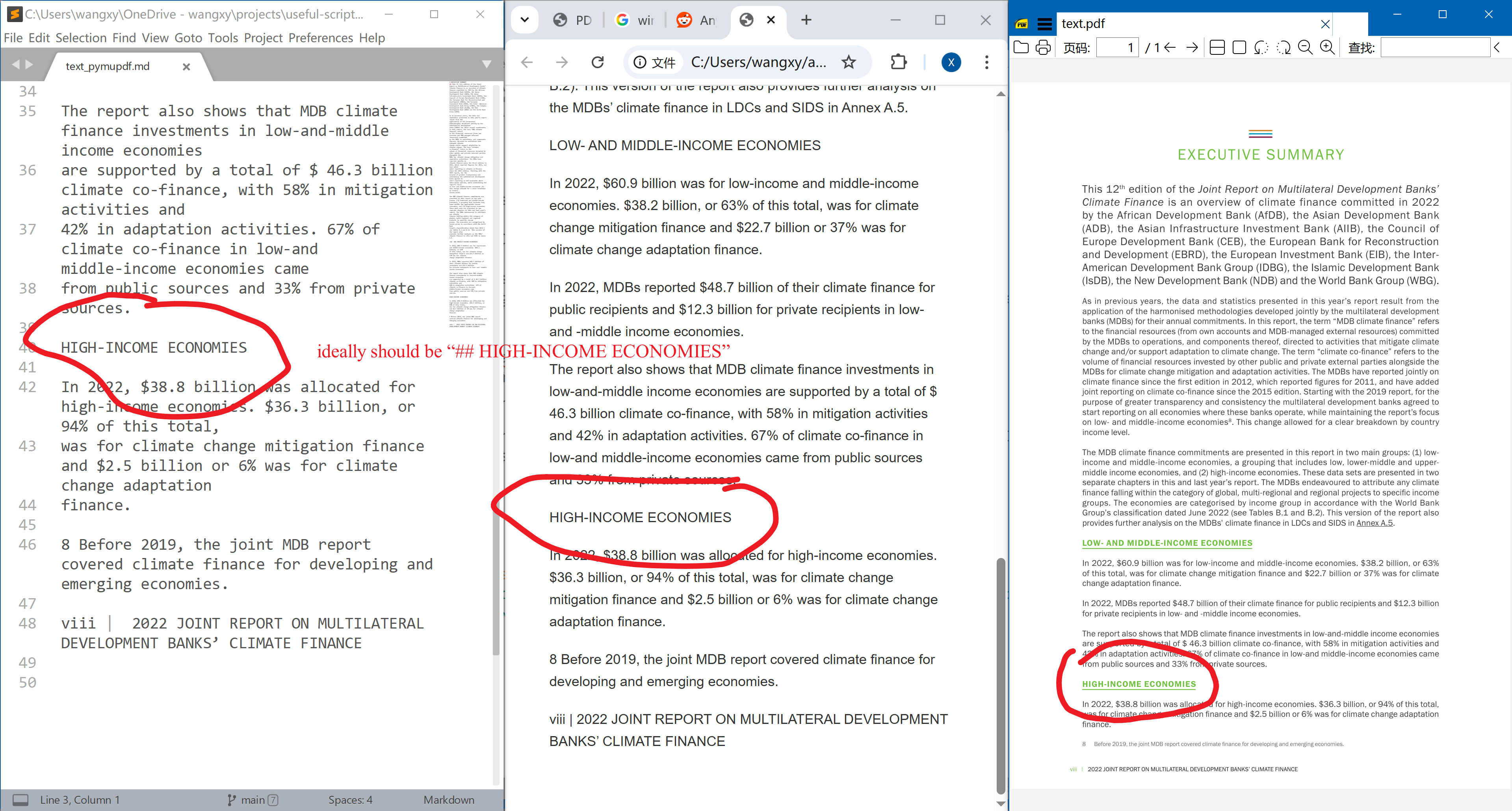
It also fails terribly at vector images.
MarkItDown
MarkItDown is from Microsoft, and it can parse files more than PDF. For office documents (e.g., .pptx), it converts them to html and then parse the page source. It also supports images, where you pay an LLM to OCR the image and get the text and structure. For PDF, it uses Pdfminer in the background, which is similar to PyMuPDF.2
It is not able to read even the simplest table in our examples.
It can’t extract images from the PDF either. (Or maybe I misread their doc.)
MinerU
MinerU from Shanghai AI lab differs from two packages above (He et al., 2024; Wang et al., 2024). It exploits machine learning methods to read PDFs, e.g. CV for page layout detection. It does relatively well in all examples, except that the footnotes are always lost.
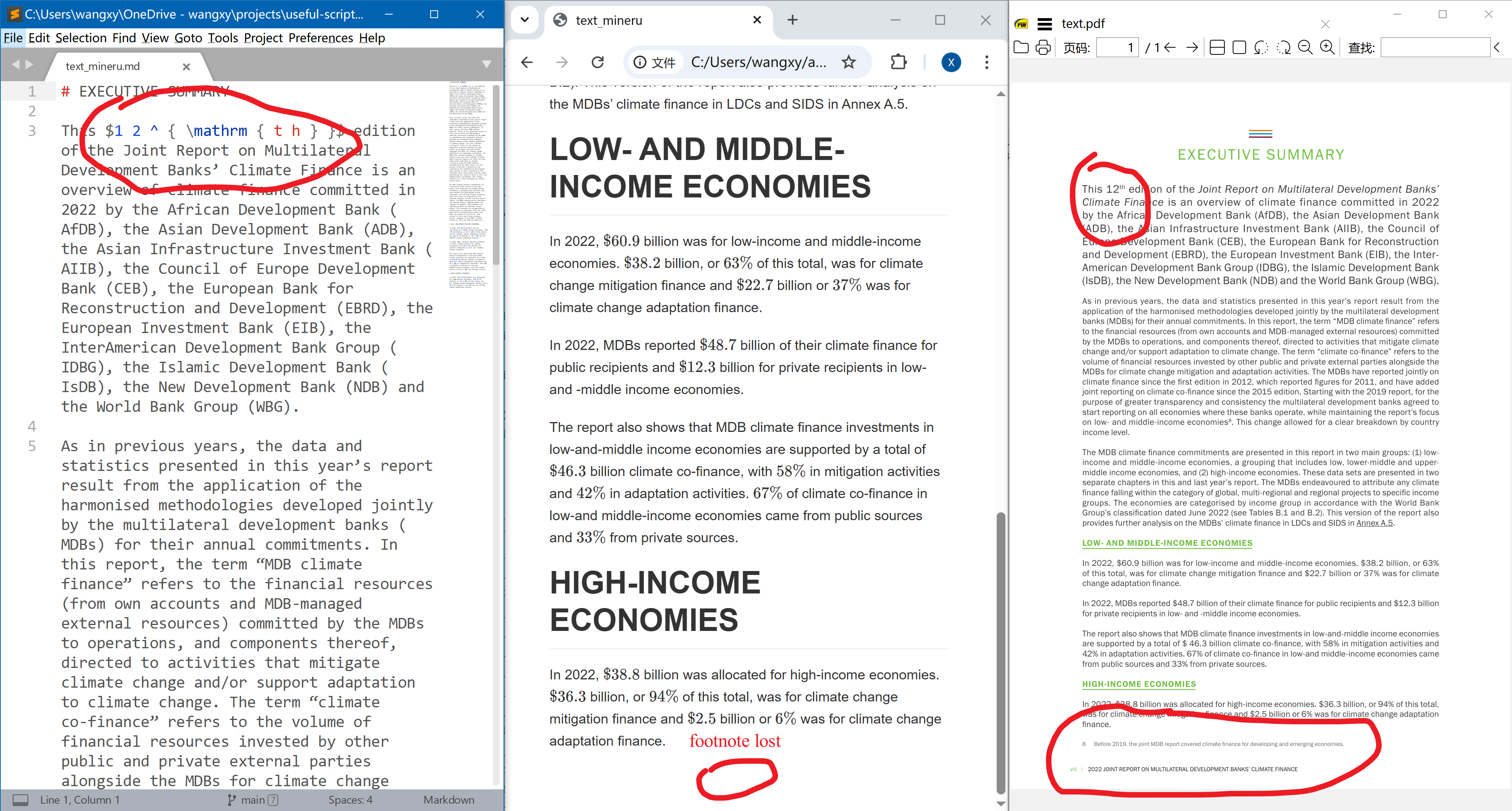
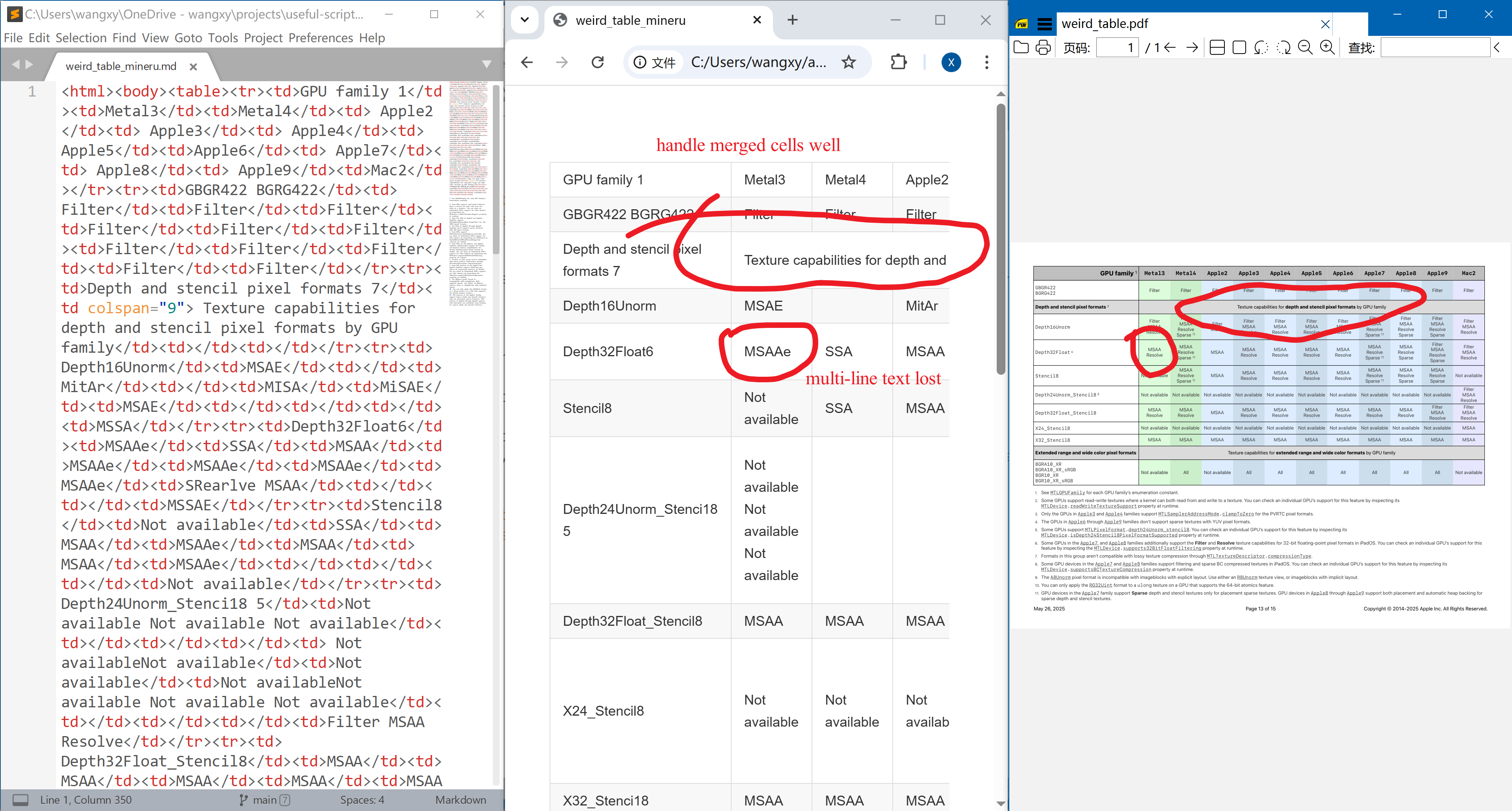
It is the only package that parses merged cells correctly. It uses HTML tables rather than native Markdown tables, which by construction does not support merged cells. However, when a cell contains multi-line text, some texts are lost. This seems a big problem to me: it may be ok-ish if we screw up the structure/format, but losing text is never OK.
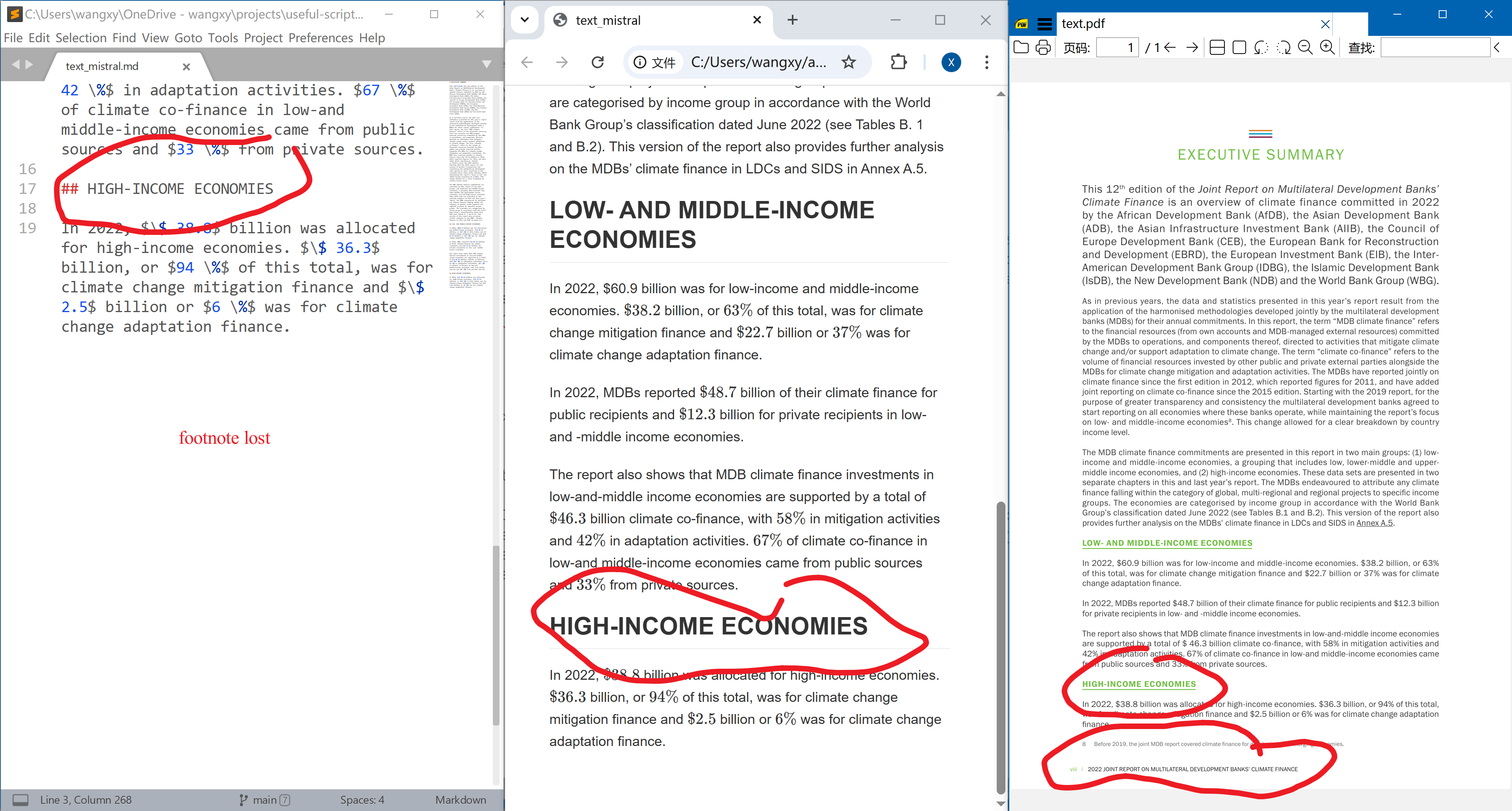
Mistral OCR
Mistral OCR is an API to convert PDF to Markdown. I don’t find much useful technical details about it, but it seems to use some multimodal LLM to read the PDF. It’s really good for pure text PDF, though footnotes are also lost.
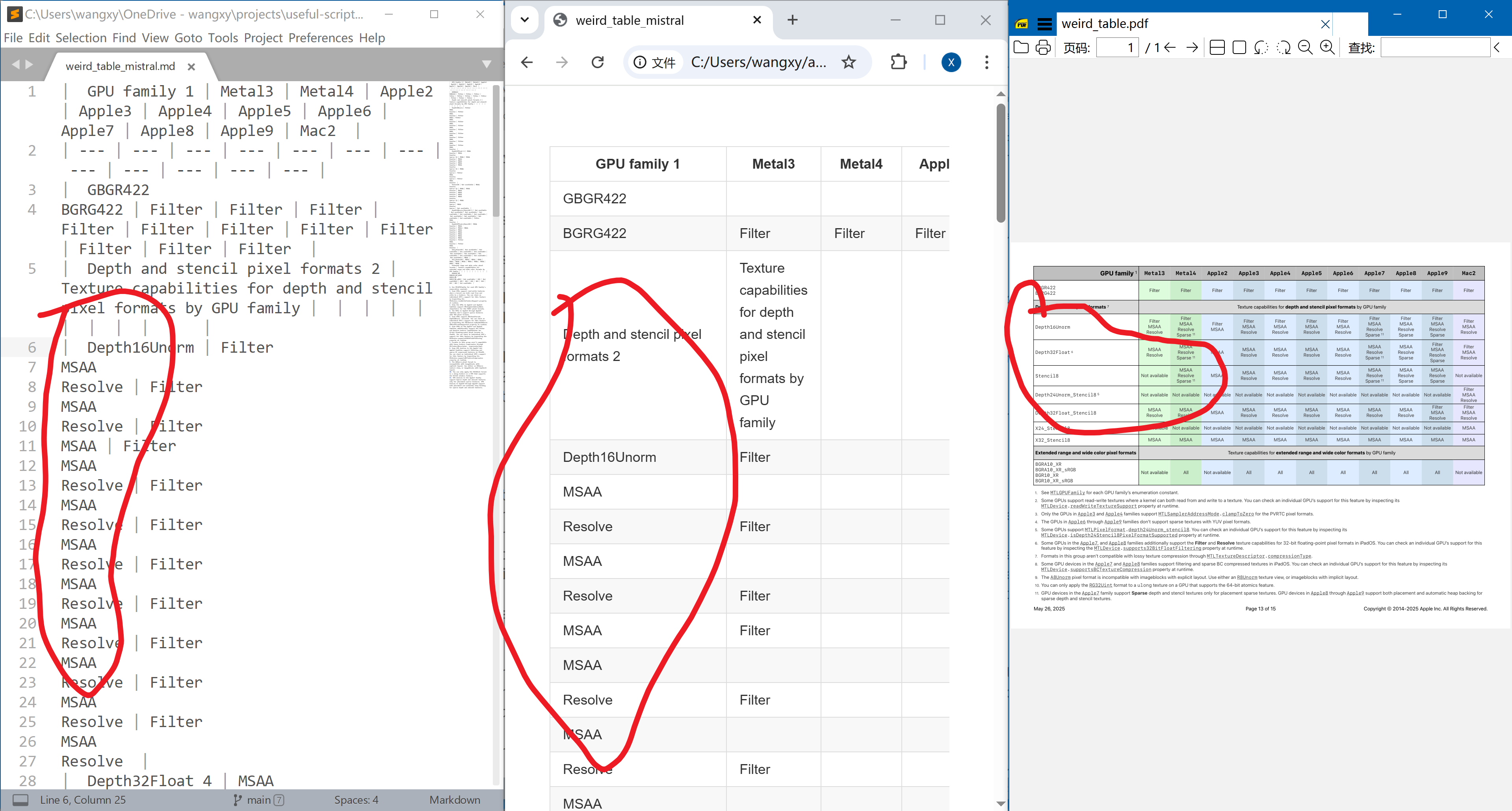
It also fails at tables with merged cells.
Docling
Docling from IBM performs the best in my test. There are mainly two components for parsing: (1) PDF backends that get all objects from the PDF (similar to PyMuPDF), and (2) machine learning models to handle tables, OCR, etc. Auer et al. (2024) gives a concise and very clear explanation of their method. There are some small problems. First of all, the footnotes are processed as normal text, and page footers are lost.
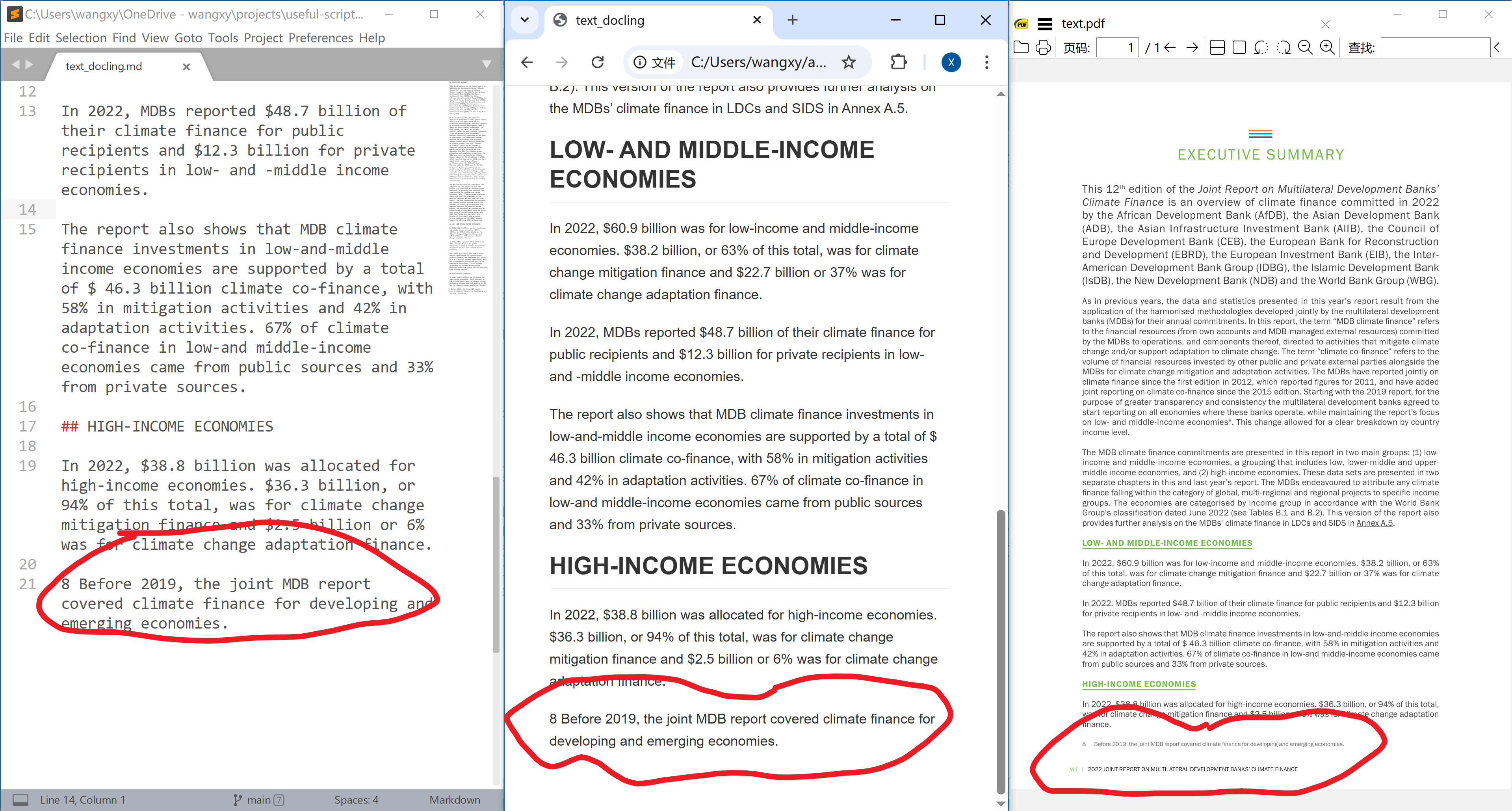
The superscripts in cells in tables are treated as normal text. This can bring confusion to later use.
Summary
| PyMuPDF4LLM | MarkItDown | MinerU | Mistral OCR | Docling | |
|---|---|---|---|---|---|
| use ML? | $\times$ | $\times$ | $\checkmark$ | $\checkmark$ | $\checkmark$ |
| image | $\times$3 | $\times$ | $\checkmark$ | $\checkmark$ | $\checkmark$ |
| simple table | borderline $\checkmark$ | $\times$ | $\checkmark$ | $\checkmark$ | $\checkmark$ |
| complicated table | $\times$ | $\times$ | $\times$4 | $\times$ | $\checkmark$ |
| section title | $\times$ | $\times$ | $\checkmark$ | $\checkmark$ | $\checkmark$ |
| footnote5 | $\checkmark$ | $\checkmark$ | $\times$ | $\checkmark$ | $\checkmark$ |
| footer5 | $\checkmark$ | $\checkmark$ | $\times$ | $\times$ | $\times$ |
| superscript | $\times$ | $\times$ | $\checkmark$ | $\checkmark$ | $\times$ |
-
harningle/fia-doc is one example where I tune the package for documents from FIA. It’s truly simple but very tedious and time consuming to address all the tiny points for parsing PDFs. ↩
-
https://dev.to/leapcell/deep-dive-into-microsoft-markitdown-4if5 walks through the high level structure of MarkItDown very well. ↩
-
OK for raster images. Can’t handle vector images at all. ↩
-
Doesn’t work for multi-line text in cells. Otherwise OK. ↩
-
None of them is able to treat footnotes/footer as footnotes/footer. Some of them can parse footnotes as main text, while others miss footnotes entirely. ↩ ↩2